
Menschen sind ziemlich schlecht darin, von KI generierte Texte zu erkennen. Aber sie können es lernen. Schon ein paar Versuche und Irrtümer reichen aus, um diese Fähigkeit um zehn Prozentpunkte zu verbessern. Außerdem sind Menschen schlecht darin, einzuschätzen, wie schlecht sie bei dieser Aufgabe sind, aber sie können es auch lernen.
https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0333007
9 Kommentare
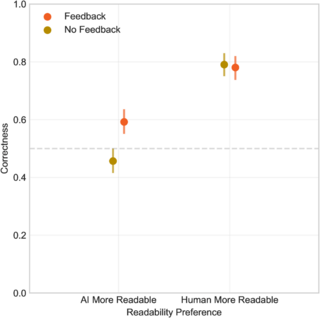
People have prejudices about LLM-generated texts. For example they think that the more readable a text is the greater chance a human has written it. So if they think that some text well well-written and readable, they suppose a human must have written it. These assumptions are not very helpful, but it is quite easy to unlearn them. You just let them guess and after each trial tell them, whether they were right or wrong. This feedback makes their performance much better.
Also, people have false assumptions about their abilities. They are too confident and they are most confident exactly when they should not be. Again, it takes just a couple of trials to calibrate properly.
10 percent improvement doesn’t impress me
It may be easier in Czech. Most large language models are primarily trained on English text. A lot of the quirks I’ve noticed are going to vary from language to language. Like how ChatGPT overuses the long dash “—“ . Maybe that dash makes more sense in another language.
The models in general are too positive and polite. Another quirk I’ve noticed is large language models overuse emojis. If I see a YouTube comment with two emojis at the end complementing the creator of the video, it’s almost always a spam bot using a large language model.
This seems short lived, just add this to the training data and the next gen ai won’t have the same tells.
I’m sure we could train an ai to detect ai generated texts
My personal rule is that if the English is too good, too few grammar, spelling or punctuation errors, it’s either a bot or a European.
OK guys, in case you want to try the experiment, here is a new English version:
[https://hypertext.cz/experiment/](https://hypertext.cz/experiment/)
The texts are authentic human British English text vs. GPT-4o trying to imitate the them.
You’ll be randomly devided into feedback / no feedback group so if you want to learn on fly and you are in the no-feedback group, just reload the app.
The web interface is wibe-translated so there might be some mistakes…
Have fun!
I can’t help but assume „errrors“ in the title was intentional. Or maybe I’m just good at picking out misspelled words — haha. (emdash included for hilarity)
On the test I got 15 out of 20 (in fact, exactly the first 15 out of 20 they showed me) correct.
Didn’t read the paper beforehand, figured incorrectly while taking the text that some of these text samples might have been LLaMA instead of GPT.
Things I considered as tells of human authorship:
1. Citations of any kind if they looked remotely valid.
2. Details strongly suggesting embodied cognition (sensory stream-of-consciousness, sense of time progression), especially when those details were coherent.
3. Single strong, outlier flavor to the text – strong and consistent idiolect; excessive academic verbosity (every other word ends in „-ation“ even though one could avoid structuring those sentences that way); other unusual register.
4. Singular emotive tone.
Things I considered as tells of LLM authorship:
1. Speaking in generalities and especially without making commitments to personal identity.
2. „Meso-complexity“ diction, neither especially sophsticated nor idiosyncratically basic. „Safe“ word choices throughout. Inoffensive corporate flavor.
Things I should have considered but didn’t for LLM authorship:
1. Excessive repetition.