
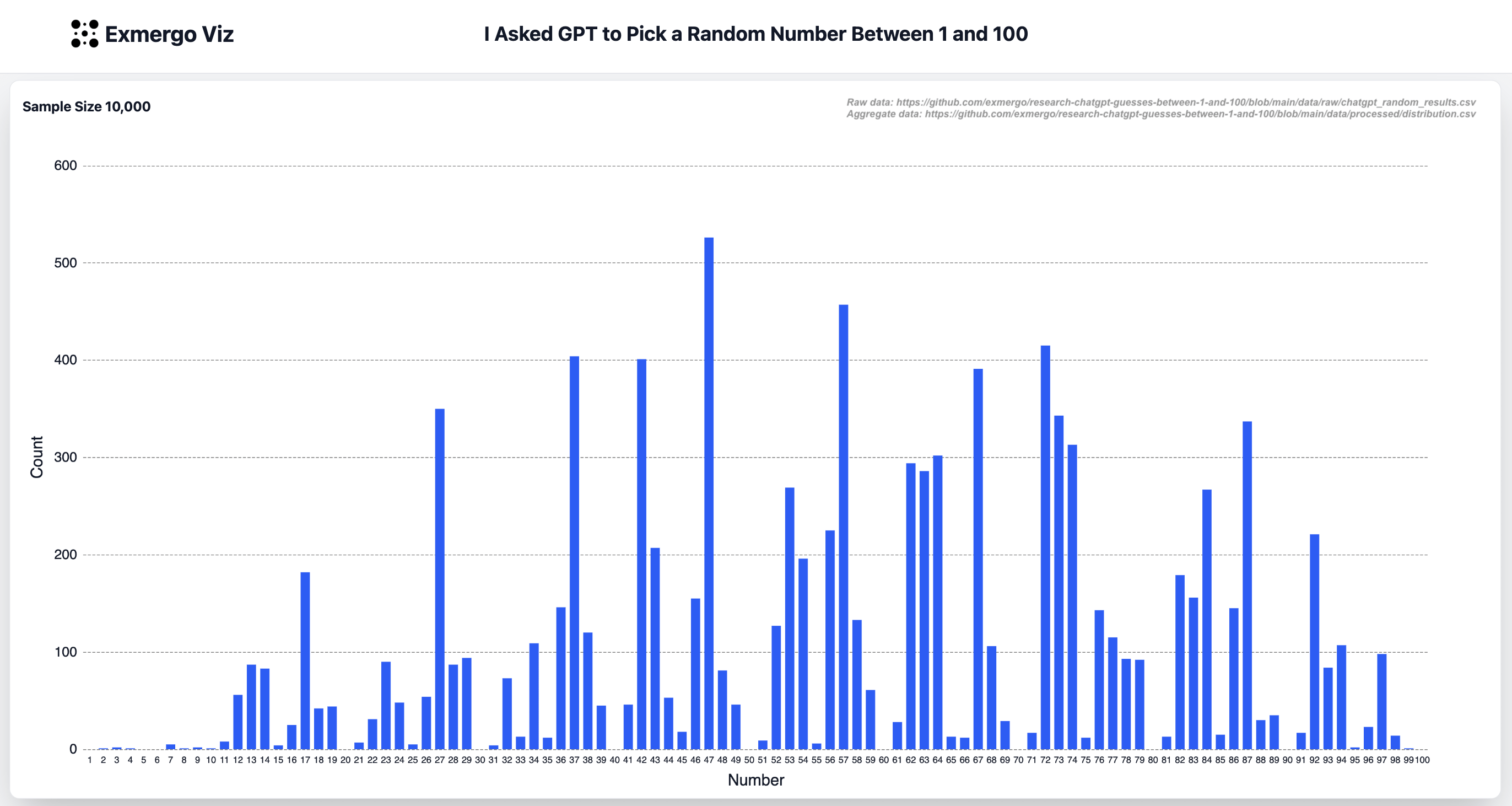
Ich habe GPT-4.1 gebeten, eine Zufallszahl zwischen 1 und 100 auszuwählen. 10.000 Mal.
Dieser Beitrag ist ein "KI-Remix" eines sehr beliebten Reddit-Beitrags hier auf r/dataisbeautiful wo den Leuten die gleiche Frage gestellt wurde: https://www.reddit.com/r/dataisbeautiful/comments/iiafkd/oc_i_asked_100_people_to_pick_a_number_between/
Menschen neigen auch dazu, keine besonders guten Zufallszahlengeneratoren zu sein.
Ich wollte sehen, ob ein KI-Modell ähnliche Tendenzen aufweist oder ob es stattdessen statistischer Strenge folgt.
Einige Dinge, die ich interessant fand:
- 20, 30, 40 und andere Vielfache von 10 wurden 0-mal ausgewählt (mit Ausnahme von 10 selbst, die einmal ausgewählt wurde).
- 42 wird 4x in der erwarteten Uniform ausgewählt (Referenz „Per Anhalter durch die Galaxis“)
- Zahlen, die die Ziffer 7 enthalten, werden zu oft ausgewählt (und ja, genau wie Menschen wird 37 zu oft ausgewählt).
- 69 wird bei 0,29x der erwarteten Uniform unterbesetzt (meine Hypothese: Sicherheitsleitplanken während des GPT vor und nach dem Training)
Definitiv keine zufällige Gleichverteilung. Ich habe einen Chi-Quadrat-Anpassungstest gegen die Gleichverteilung durchgeführt und festgestellt, dass χ² = 15.604, p ≈ 0.
Die vollständige Methodik und den Code finden Sie in diesem Open-Source-Repo: https://github.com/exmergo/research-chatgpt-guesses-between-1-and-100
Ich habe das OpenAI SDK verwendet, um GPT-4.1 10.000 Mal programmgesteuert mit derselben Eingabeaufforderung aufzurufen.
Ich habe GPT-4.1 verwendet, weil es ein nicht-logisches Modell ist, das einen Temperaturparameter offenlegt. Ich habe die Temperatur = 1,0 eingestellt; Das macht die Stichprobenverteilung des Modells zu dem, was ich tatsächlich messe. Die Argumentationsmodelle von OpenAI beschränken diesen Parameter. Es wäre interessant, dieses Experiment mit Argumentationsmodellen zu reproduzieren.
Für die Datenvisualisierung habe ich Viz verwendet, unseren eigenen Diagramm-/Dashboard-KI-Agenten: Exmergo Viz
Von marco-exmergo
4 Kommentare
Why not plot it against the human dataset?
Huh. It actually gave you ‚random-sounding‘ numbers – the sort of numbers you’d find in scraping a bunch of text for situations where someone gave an example of a number that was ‚random‘ – rather than using a random-number generator.
What an interesting example of another potential pitfall of AI use.
I’m actually surprised it only picked numbers between one and 100
Interesting, looks like the 27 bias got better.