
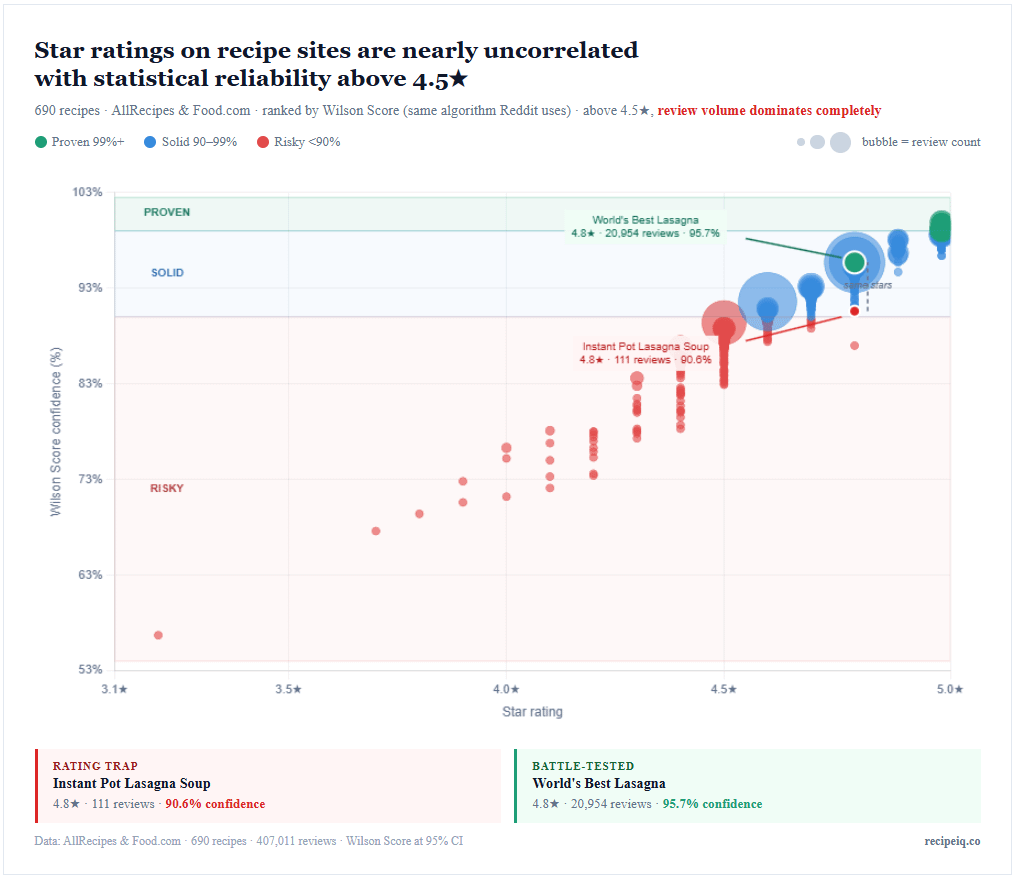
Jede Blase ist eines von 690 Rezepten von AllRecipes und Food.com. Die X-Achse ist die Sternebewertung, die Y-Achse die Wilson-Score-Konfidenz und die Blasengröße die Anzahl der Bewertungen.
Das Ergebnis: Über 4,5★ sagt die Sternebewertung fast nichts aus. Zwei Rezepte wurden jeweils mit 4,8★ bewertet – eines hat 111 Bewertungen (90,6 % Sicherheit), eines hat 20.954 Bewertungen (95,7 % Sicherheit). Gleiche Sterne. Völlig andere Zuverlässigkeit.
Wilson Score Lower Bound fragt: Wie hoch ist angesichts dieser Bewertung UND dieser vielen Rezensionen die Wahrscheinlichkeit, dass dieses Rezept im ungünstigsten Fall tatsächlich gut ist? Derselbe Algorithmus, den Reddit zum Ranking von Kommentaren verwendet.
Von Content-Ad-8858
3 Kommentare
Anytime I hear tells the whole story I know a certain agent wrote this.
Unlike some I don’t always have a problem with that but it should always be noted in the citation.
Op which model made this and why is that not noted?
We gotta ban the slop, it is not beautiful
The conclusion is kind of uninteresting. The spread for high star ratings is no greater than for lower star ratings. A dish rated above 4.5 stars is almost certainly good. And the higher the rating goes above 4.5 stars, the more likely it’s good.
It’s not interesting that recipes with higher review counts have a higher lower bound of the proportion confidence interval, it’s just math. If 90% of people rated two recipes positively, but the rating was among 10 people for the first and 1000 for the second, then of course you have more confidence that the second one is better.
The lower bound of the CI is not the „best estimate“ of a recipe’s quality, though, that’s the mean rating. With the CI rating, it’s impossible for recipes that aren’t popular to rate well. This is basically the whole point of the Wilson interval score, to put more confidence where you see more data. This isn’t unique to recipes, you are mathematically guaranteed to see this pattern in any type of rating data.
If two of anything are rated 5 stars, obviously you should be more sure of the one with more ratings. For *every* individual star rating, the y-axis is simply organized by the number of reviews. It’s not unique to >4.5 stars.