



Wie genau ist die KI-Kalorienverfolgung? Ich wollte echte Zahlen, also ließ ich 3.490 im Labor abgewogene Mahlzeiten aus dem Nutrition5k-Datensatz von Google Research über dieselbe Pipeline laufen, die ein echter Benutzer meiner App erhält. Gemini 3.1 Pro, Zero-Shot, strukturierte JSON-Ausgabe. Keine Feinabstimmung. Die vollständige Methodik, Datensatzabweichung, Kontaminationsoffenlegung und Iterationsverlauf finden Sie im obersten Kommentar.
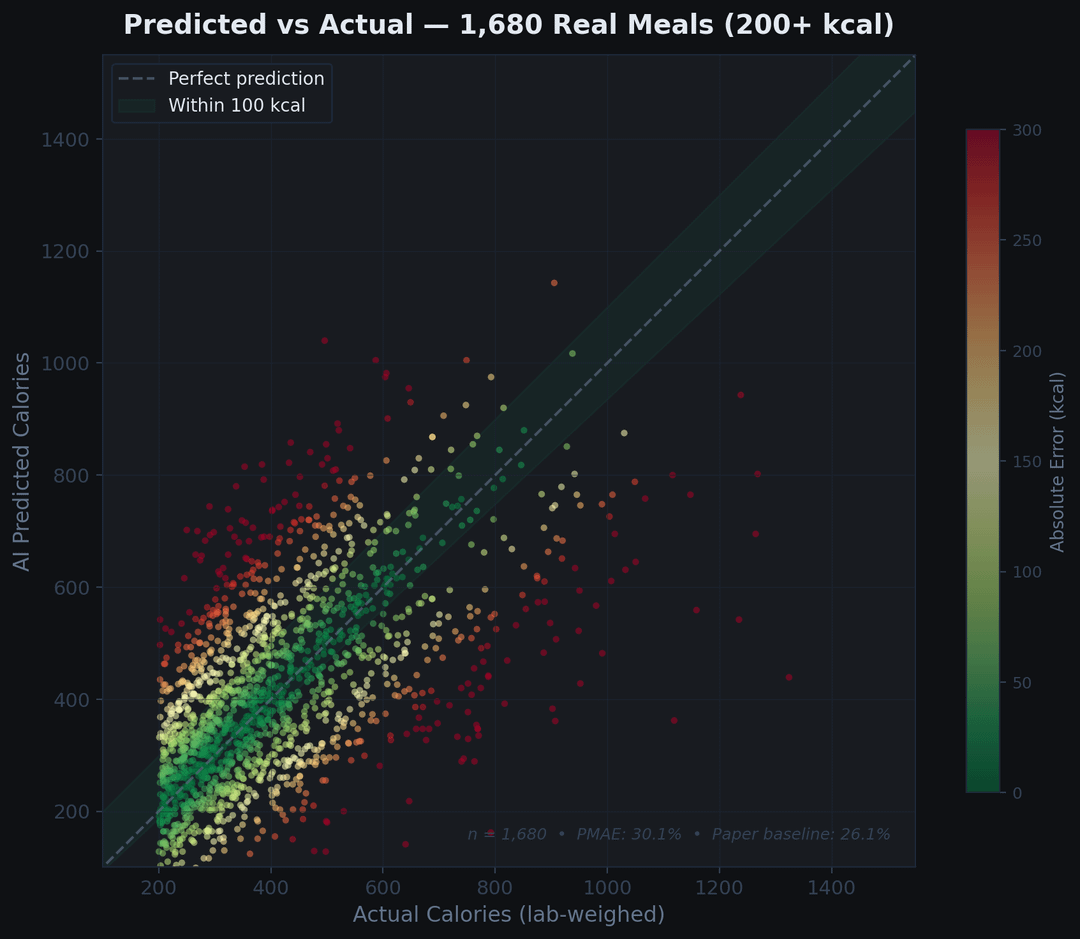
Kurzfassung: Der mittlere Fehler beträgt 57 kcal pro Gericht, 66 % der Vorhersagen liegen innerhalb von 100 kcal von der Wahrheit und die Massenschätzung (24,8 % PMAE) liegt innerhalb von 3 Punkten eines speziell auf diesem Datensatz trainierten CV-Modells. Der Kaloriengehalt beträgt insgesamt 42,1 % und bei echten Mahlzeiten mit mehr als 200 kcal 30,1 %, im Vergleich zum trainierten Basiswert der Studie von 26,1 %. Die Lücke ist fast ausschließlich auf die unsichtbare Kaloriendichte zurückzuführen – die Fettschätzung liegt bei 58 %, weil man auf einem Foto kein Speiseöl sehen kann.
Mehr von mir, einschließlich der Diskussion über Datenkontamination, im Top-Kommentar.
Projektseite: https://snapNutrition.app
Von Opticplex3
6 Kommentare
Methodology and data:
Dataset: Nutrition5k (Thames et al., CVPR 2021), 3,490 cafeteria dishes with every ingredient individually lab-weighed. Overhead RGB photos from a RealSense camera.
Model: Gemini 3.1 Pro (google-genai SDK, Vertex AI). Temperature 0. Thinking level LOW. Structured JSON output via response_schema matching my production app’s schema. Same prompt every real user gets. Zero-shot, no fine-tuning.
Metrics: PMAE = Mean Absolute Error / Mean Ground Truth × 100 (the metric from the original paper). „Per-dish %“ = |predicted − actual| / actual × 100 per dish, then median or mean. These give different answers because the dataset has 1,199 sub-100-kcal dishes that blow up per-dish percentages.
Cost: $49.71 total (~$0.014/dish) on Pro pricing. 14.3M input tokens, 1.8M output tokens. Also ran Gemini 3 Flash (thinking=minimal) at $10.61 for comparison — details below.
Why Pro LOW for production: Pro LOW matches Flash default thinking on accuracy (42.1% vs 43.0%, within noise) but runs 2× faster (13.9s vs 28.2s per dish) at similar cost. In a user-facing app, cutting latency in half for the same accuracy was an easy call.
DATA CONTAMINATION DISCLOSURE: Nutrition5k is a public Google dataset and Gemini is a Google model. I can’t prove the base model never crawled the dataset during pretraining — it’s been on GitHub since 2021. What I can say: if the model had meaningfully memorized it, we’d expect near-zero recall error, not 42.1% PMAE that TRAILS the paper’s trained baseline by 16 points. A memorized lookup would beat a trained CNN, not lose to it. Treat this as „zero-shot-ish with unknown contamination risk“ rather than strictly held-out.
Absolute error percentiles: P10: 6 kcal, P25: 20 kcal, P50: 57 kcal, P75: 137 kcal, P90: 248 kcal, P95: 346 kcal. Over-prediction rate 61.4%, mean signed error +34.3 kcal.
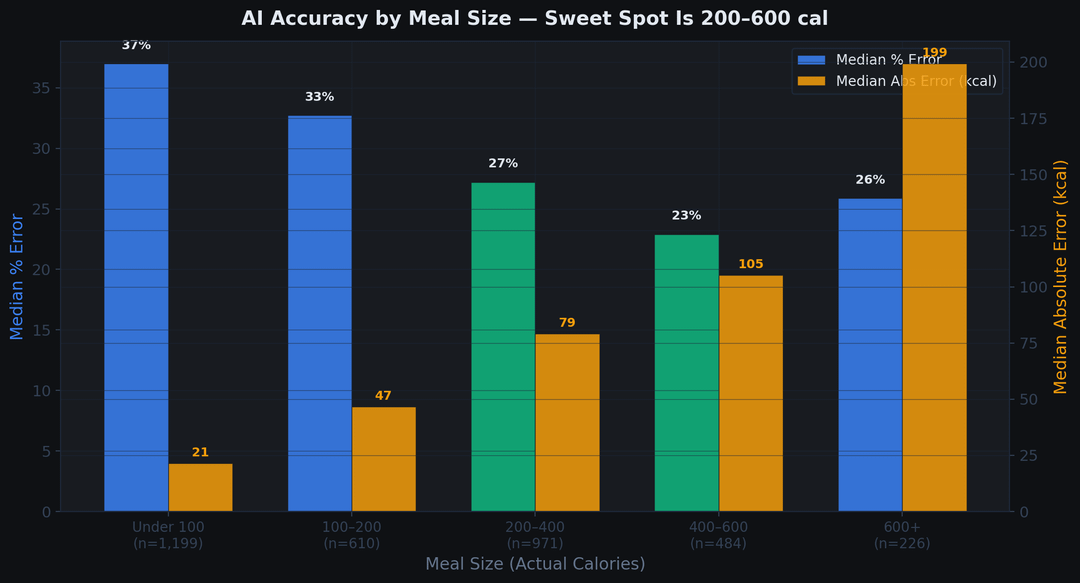
Accuracy by meal size (median abs / median %):
– <100 kcal (n=1,199): 21 kcal / 37%
– 100–200 kcal (n=610): 47 kcal / 33%
– 200–400 kcal (n=971): 79 kcal / 27%
– 400–600 kcal (n=484): 105 kcal / 23%
– 600+ kcal (n=226): 199 kcal / 26%
Charts made with matplotlib (Python). Raw dish-level predictions (JSONL, 3,490 entries) available if anyone wants to reproduce or run their own analysis. DM me.
Love data like this! Really interesting stuff, thanks for posting.
Really solid methodology here. The 57 kcal median error is impressive for zero-shot, but the fat estimation gap (58% PMAE) is the real insight — it highlights a fundamental limitation of visual-only analysis.
I work with AI models for a different domain (analyzing web content across 12 languages for SEO) and we hit similar „invisible data“ problems. Text that looks identical on the surface can have completely different semantic weight depending on language and cultural context — similar to how a dish can look low-calorie but be loaded with hidden oil.
The contamination disclosure is refreshing. Most benchmarks skip that entirely. Did you consider testing with dishes that are visually similar but calorically different (e.g., diet vs regular versions) as an adversarial set? That would really stress-test the model’s limits.
I’ve been using Gemini to count calories for ages myself! (For free mind you)
Checking the results myself against my best effort research and comparing my expected weight loss to actual weight loss, I’ve come to the conclusion that: while yes there are pretty significant error bars for each food item, because the error goes both ways, the aggregate daily calorie counts are pretty much spot on!
Early Bard was not like this and DRAMATICALLY undercounted my calorie intake, typically rounding items to the nearest 50 calories for some reason. I gained 5 pounds using that model. Same for og chatGPT 3.5. GPT4 was the first model to really get the counts close enough on average to be usable, and Gemini 2 or so was the first Google model to reach that benchmark for me.
I have been wary of the calorie counter ai cameras etc. If I have absolutely no idea its better than nothing but once every 2 weeks say doesnt hurt. People relying on this daily to manager hunger, lose weight responsibly etc may struggle.
If you haven’t done so already, you should really cross post this to r/loseit
„Median error“ is a poor estimate for a model performance : large errors are not affecting it, and it doesn’t take in account the initial distribution of your dataset. How about a good old fraction of explained variance (R^2), which is also easy to interpret !