
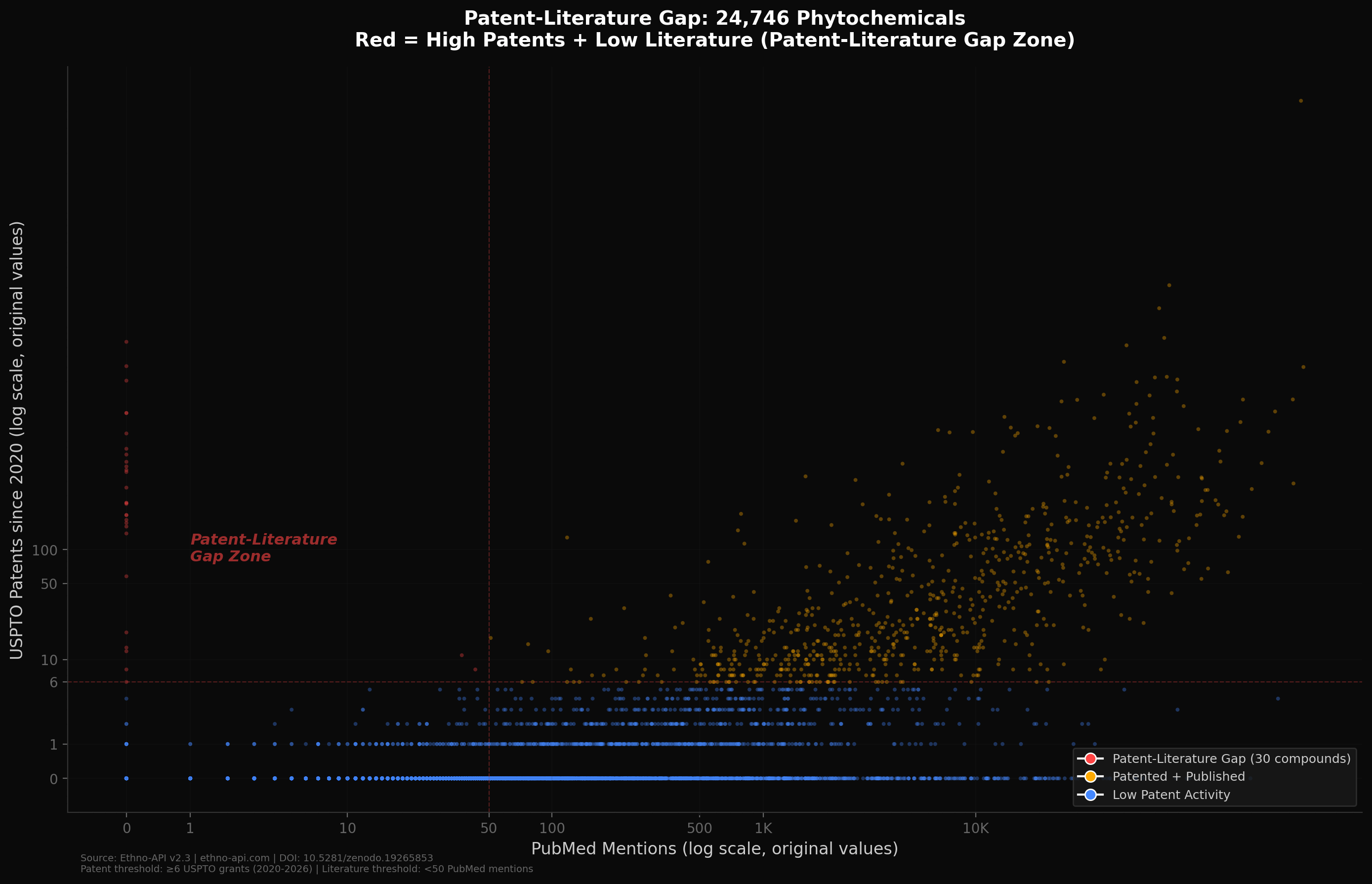
Vor ein paar Wochen habe ich eine Version dieser Tabelle mit falscher Terminologie veröffentlicht. Ich habe die Lücke angerufen "FTO-Leerzeichen" wenn es tatsächlich das Gegenteil zeigt (hohe Patentdichte, keine Handlungsfreiheit). Vielen Dank an die Community, die das mitbekommen hat. Hier ist die korrigierte Version mit den richtigen Achsenbeschriftungen und Terminologie.
Der Datensatz wird aus der phytochemischen Datenbank des USDA Dr. Duke erstellt, aus 16 CSV-Dateien denormalisiert und mit fünf öffentlichen APIs angereichert: PubMed (Zitatanzahl), ClinicalTrials.gov (Studienregistrierungen), ChEMBL (Bioaktivitätsmessungen), USPTO PatentsView (Patenterteilungen seit 2020) und PubChem (molekulare Identifikatoren).
Was das Diagramm zeigt:
Jeder Punkt ist eine von 24.746 einzigartigen Verbindungen. Die x-Achse zeigt PubMed-Erwähnungen (logarithmische Skala, Originalwerte angezeigt), die y-Achse zeigt USPTO-Patenterteilungen seit 2020 (gleiche Skala). Rote Punkte sind Verbindungen im "Kluft zwischen Patent und Literatur": sechs oder mehr Patente, aber weniger als 50 veröffentlichte Studien.
30 Verbindungen fallen in diese Zone. Sie werden kommerziell patentiert, verfügen jedoch kaum über eine von Experten überprüfte pharmakologische Charakterisierung. Für jeden, der sich mit der Zielauswahl oder Wettbewerbslandschaftsanalyse in der Entdeckung botanischer Arzneimittel beschäftigt, ist dies das Signal, das zählt.
Quelle: Ethno-API v2.3, 76.907 Verbundpflanzen-Datensätze. Die vollständige Methodik und eine Stichprobe mit 400 Datensätzen finden Sie auf GitHub.
github.com/wirthal1990-tech/USDA-Phytochemical-Database-JSON
Von DoubleReception2962
1 Kommentar
Data source: USDA Dr. Duke’s Phytochemical and Ethnobotanical Database (16 raw CSV files, denormalized and deduplicated). Enriched against five public APIs: PubMed E-utilities (citation counts), [ClinicalTrials.gov](http://ClinicalTrials.gov) API v2 (study registrations), ChEMBL v35 (bioactivity assay counts), USPTO PatentsView (grant counts since Jan 2020), and PubChem (CID + canonical SMILES via CTS synonym resolution).
Tools: Python (pandas, matplotlib, requests), DuckDB for query logic, Parquet as the storage format. The enrichment pipeline ran ~75k API calls across the five sources. SMILES coverage after CTS canonicalization: 75.4% of 24,746 unique compounds.
The full dataset (76,907 compound–species records, JSON + Parquet) is archived on Zenodo with a citable DOI: 10.5281/zenodo.19265853. A 400-record sample is on GitHub if you want to poke around without committing to the full file.
Looking forward to answer questions about the methodology. The patent matching in particular has some nuances that are worth discussing.