
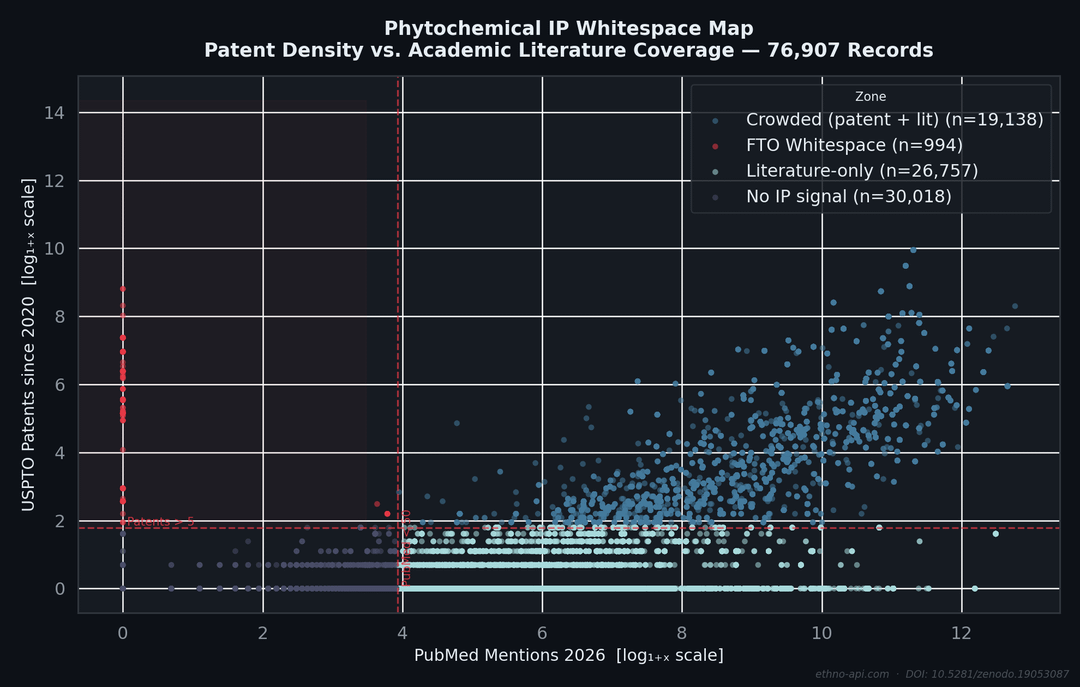
Jeder Punkt stellt einen sekundären Pflanzenstoff aus der Dr. Duke-Datenbank des USDA dar, aufgetragen gegen die seit 2020 beim USPTO angemeldeten Patente (y-Achse) und der Zitierhäufigkeit in PubMed (x-Achse). Beide Achsen sind logarithmisch skaliert.
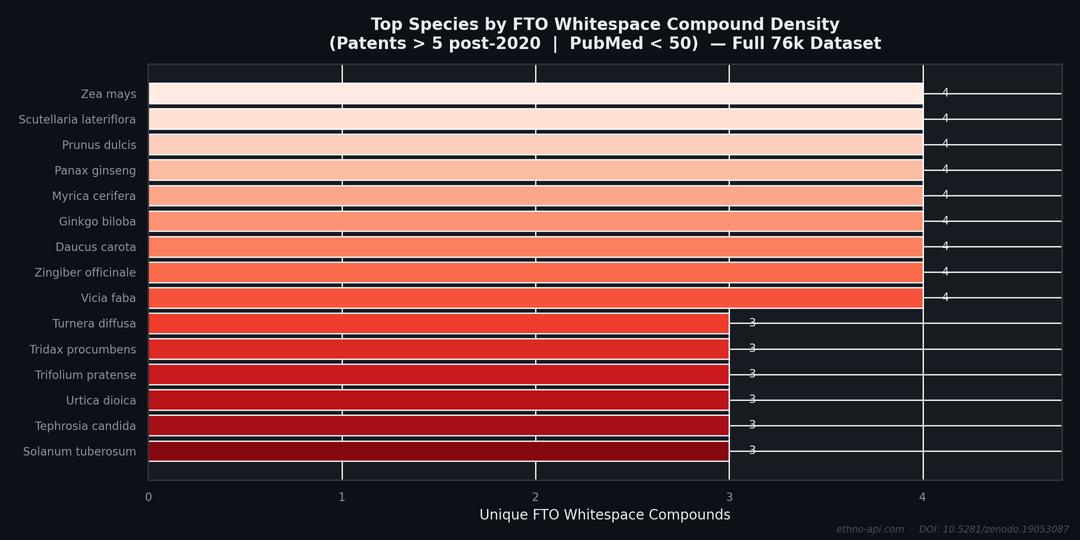
Der rote Bereich: hohe Patentdichte, wenig wissenschaftliche Literatur – das bezeichnen IP-Analysten als FTOwhitespace: kommerzielle Aktivitäten, die noch nicht zu peer-reviewten wissenschaftlichen Veröffentlichungen geführt haben. In einer Stichprobe von 400 Datensätzen gibt die Abfrage Verbindungen mit mehr als 5 Patenten und weniger als 50 Zitaten in PubMed zurück.
Erstellt aus einem flachen Datensatz von 76.000 Datensätzen, der ethnobotanische Datensätze des USDA mit PubMed kombiniert, ClinicalTrials.govChEMBL-Bioaktivitätsdaten und PatentsView. Die vollständige Pipeline ist im GitHub-Repository verfügbar, einschließlich der DuckDB-Abfrage und der ChromaDB-RAG-Einbettung.
github.com/wirthal1990-tech/USDA-Phytochemical-Database-JSON
Von DoubleReception2962
Ein Kommentar
**Source:** USDA Dr. Duke’s Phytochemical and Ethnobotanical Databases (public domain) — denormalized and enriched with:
– PubMed citation counts via NCBI E-utilities
– [ClinicalTrials.gov](http://ClinicalTrials.gov) study counts (API v2)
– ChEMBL bioactivity measurements (with PubChem InChIKey fallback)
– USPTO patent counts via PatentsView (post-2020)
Full dataset: 76,907 records across 24,746 unique compounds and 2,313 plant species.
DOI: 10.5281/zenodo.19053087
**Tool:** Python (matplotlib + seaborn), DuckDB for the FTO whitespace query. Both axes are log₁₊ₓ scaled to handle the heavy right-skew in citation counts.
**Code + methodology:**
[github.com/wirthal1990-tech/USDA-Phytochemical-Database-JSON](http://github.com/wirthal1990-tech/USDA-Phytochemical-Database-JSON)
The full pipeline including the DuckDB query used to classify compounds into the four zones (FTO Whitespace / Crowded / Literature-only / No IP signal) is documented in [METHODOLOGY.md](http://METHODOLOGY.md) in the repo.